The stories of seven important but lesser known pioneers in personal computing, video games, advanced semiconductor logic, modern venture capital, and biotechnology during the 1960s-1980s. 4/5
How various parts of the US constitution thwarts the will of an expanding multicultural majority in favor of a shrinking rural white minority. Interesting 3/5
Explains the demographic transition and how it has flowed from the UK to Europe to the rest of the world and how this has and will influence history. 3/5
$895 to Givewell Top Charities fund . I’ve been donating to Givewell as my main “help the poor” charity since they have fairly low overheads and try and get the most impact from their donations. They also get good reviews for living up to these goals.
My employer matched this donation so total given to Givewell was $1790.
Software and Internet Infrastructure Projects
Software in the Public Interest, The Software Freedom Conservancy and LibreOffice all use Paypal which is blocking charity donations from Asia/Pacific so I was unable to donate to them.
€20 to Syncthing which I use to Sync files between my computers and phone since I stopped using Dropbox.
$NZ 200 to The Spinoff which is a New Zealand news website. I usually donate $100/year but I did a extra $100 one-off since they are having funding problems
Delivers on the title. Interesting explanations of types of lakes, how they came to be and how they evolve. Great writing and lots of interesting information 4/5
A Veteran TV Writer and Showrunner writes about his career, the business and how to make it as a TV writer and possibly eventually a showrunner. Excellent 4/5
A Star Trek parody from the POV of five ensigns who realise something is very strange on their ship. Plot moves steadily and the humour and action mostly work. 3/5
An account of the discover and lives of Neanderthals, Denisovans and others hominids who shared the earth with Homo sapiens in the last 300,000 years. 4/5
Since it opened in 2017 Parnell Station has been one of the least busy stations in Auckland. In the year to June 2019 there were just 168,000 boardings at the Station, ranking 36th out of 40 stations on the network.
While the suburb of Parnell is fairly high density and has a good mixture of retail, entertainment, office and residential is it under-served by the station.
Parnell Station’s main problem is that it is in a valley with the Auckland Domain on one side and a steep hill to Parnell Road on the other. The way up the hill is steep, indirect and is not suitable for people with mobility issues. The route to the museum is a rough walking track. There is a dedicated path to the Carlaw Park student village and business centre however.
The poor accessibility to the main Parnell Road shopping/business area and even worse access to the St Georges Bay Road business area have hurt the station’s usage. These problems have been written about previously on Greater Auckland, twice.
A wheelchair accessible underpass between the two platforms was added to the station in early 2024. This enabled safer and easier transfer between platforms and to access to the boardwalk to Carlaw Park. However the hill to Parnell Road is still a problem.
A Possible Solution – A Pedestrian Tunnel
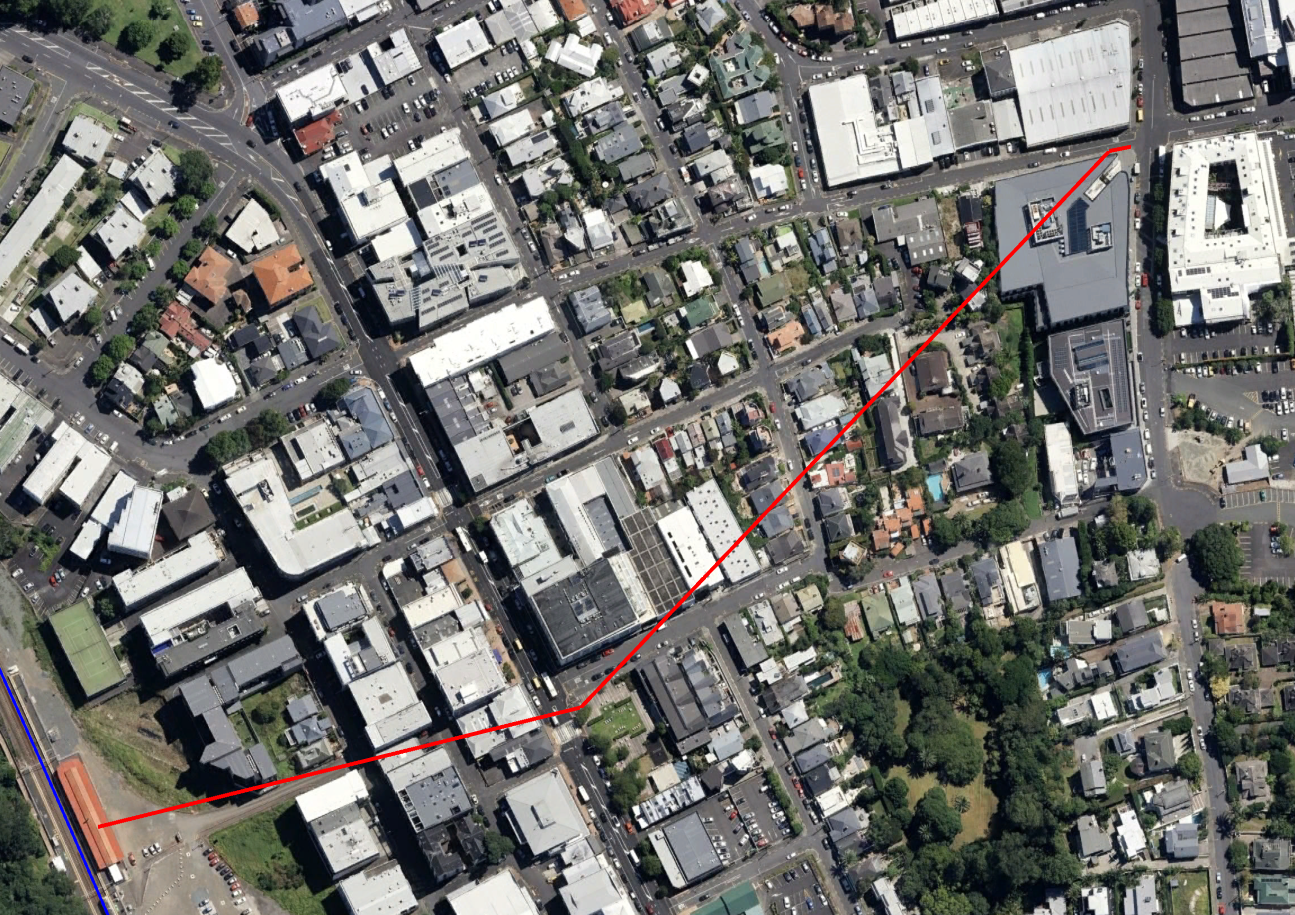
My proposal is a pedestrian tunnel running from near the Parnell Station to the North-West under the main hill and emerging on St Georges Bay Road. Around the middle of the tunnel there would be elevators going up to Parnell Road. The tunnel would be around 550 metres long. The ends are at similar heights so the tunnel would be relatively flat while the central elevators would need to travel around 20 metres. The tunnel should be wide, well-lit and have security cameras etc to make people using it feel safe.
The elevators would be around 3 minutes walk from Parnell Station on 4-5 minutes from St Georges Bay Road. I’ve place the street level access to the elevators in Heard Park on the corner of Parnell Road and Ruskin Street (at the bend in the above map). Probably several elevators would be required for redundancy and since traffic will probably be bursty.
The St Georges Bay Road entrance could be at the bottom of Garfield Street. It would probably be easiest to take up some street/footpath space and run parallel to the road before turning South-West once significantly deep. There are several hundred jobs within a couple of minutes walk of this entrance. There is also a Saturday Market nearby.
Overall the project should be only moderately expensive to build and improve the catchment and value of Parnell Station as well as linking three parts of Parnell better together.
This Blog is about a variety of topics that I’m interested in. My top posts are listed below. I also do regular posts on Audiobooks I’ve listened to and notes from conferences I attend.