Each year I do the majority of my Charity donations in early December (just after my birthday) spread over a few days (so as not to get my credit card suspended).
I also blog about it to hopefully inspire others. See: 2019, 2018, 2017, 2016, 2015
All amounts this year are in $US unless otherwise stated
My main donations was $750 to Givewell (to allocate to projects as they prioritize). Once again I’m happy that Givewell make efficient use of money donated. I decided this year to give a higher proportion of my giving to them than last year.
Software and Internet Infrastructure Projects
€20 to Syncthing which I’ve started to use instead of Dropbox.
I’ve been using Keda a little bit at work. Good way to scale on random stuff. At work I’m scaling pods against length of AWS SQS Queues and as a cron. Lots of other options. This talk is a 9 minute intro. A bit hard to read the small font on the screen of this talk.
Outlines some new stuff in scaling in 1.18 and 1.19.
They also have a fork of the Cluster Autoscaler (although some of what it seems to duplicate Amazon Fleets).
Have up to 1000 nodes in some of their clusters. Have to play with address space per nodes, also scale their control plan nodes vertically (control plan autoscaler).
Use Virtical Pod autoscaler especially for things like prometheus that varies by the size of the cluster. Have had problems with it scaling down too fast. They have some of their own custom changes in a fork
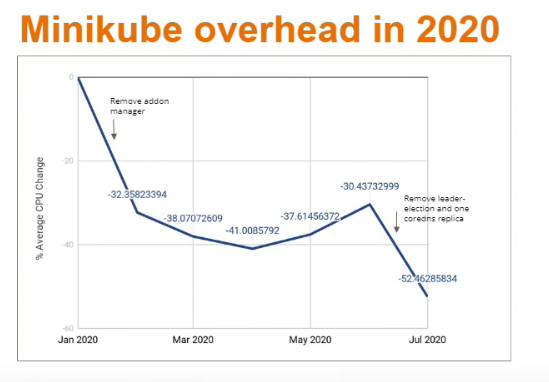
Could increase addon manager polltime but then addons would take a while to show up.
But in Minikube not a problem cause minikube knows when new addons added so can run the addon manager directly rather than it polling.
32% reduction in overhead from turning off addon polling
Also reduced coredns number to one.
pprof – go tool
kube-apiserver pprof data
Spending lots of times dealing with incoming requests
Lots of requests from kube-controller-manager and kube-scheduler around leader-election
But Minikube is only running one of each. No need to elect a leader!
Flag to turn both off –leader-elect=false
18% reduction from reducing coredns to 1 and turning leader election off.
Back to looking at etcd overhead with pprof
writeFrameAsync in http calls
Theory could increase –proxy-refresh-interval from 30s up to 120s. Good value at 70s but unsure what behavior was. Asked and didn’t appear to be a big problem.
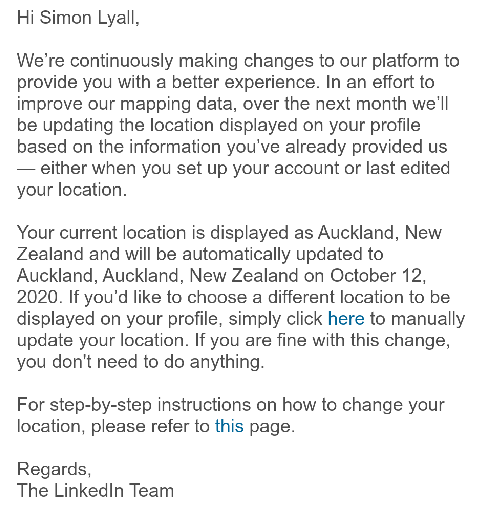
I got this email from Linkedin this morning. It is telling me that they are going to change my location from “Auckland, New Zealand” to “Auckland, Auckland, New Zealand“.
Email from Linkedin on 30 August 2020
Since “Auckland, Auckland, New Zealand” sounds stupid to New Zealanders (Auckland is pretty much a big city with a single job market and is not a state or similar) I clicked on the link and opened the application to stick with what I currently have
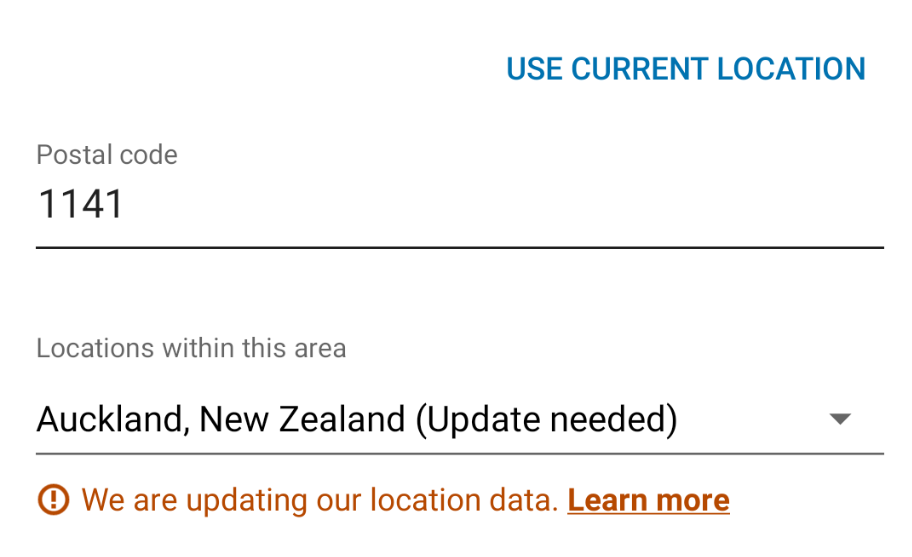
Except the problem is that the pulldown doesn’t offer many any other locations
The only way to change the location is to click “use Current Location” and then allow Linkedin to access my device’s location.
By default, the location on your profile will be suggested based on the postal code you provided in the past, either when you set up your profile or last edited your location. However, you can manually update the location on your LinkedIn profile to display a different location.
but it appears the manual method is disabled. I am guessing they have a fixed list of locations in my postcode and this can’t be changed.
So it appears that my options are to accept Linkedin’s crappy name for my location (Other NZers have posted problems with their location naming) or to allow Linkedin to spy on my location and it’ll probably still assign the same dumb name.
The basically appears to be a way for Linkedin to push user to enable location tracking. While at the same time they get to force their own ideas on how New Zealand locations work on users.
At the start of 2011 Uber was in one city (San Francisco). Just 3 years later it was in hundreds of cities worldwide including Auckland and Wellington. Dockless Electric Scooters took only a year from their first launch to reach New Zealand. In both cases the quick rollout in cities left the public, competitors and regulators scrambling to adapt.
Delivery Robots could be the next major wave to rollout worldwide and disrupt existing industries. Like driverless cars these are being worked on by several companies but unlike driverless cars they are delivering real packages for real users in several cities already.
Note: I plan to cover other aspects of Sidewalk Delivery Robots including their impact of society in a followup article.
What are Delivery Robots?
Delivery Robots are driverless vehicles/drones that cover the last mile. They are loaded with a cargo and then will go to a final destination where they are unloaded by the customer.
Indoor Robots are designed to operate within a building. An example of these is The Keenon Peanut.These deliver items to guests in hotels or restaurants . They allow delivery companies to leave food and other items with the robot at the entrance/lobby of a building rather than going all the way to a customer’s room or apartment.
The next size up are sidewalk delivery robots which I’ll be concentrating on in the article. Best known of these is Starship Technologies but there is also Kiwi and Amazon Scout. These are designed to drive at slow speeds on the footpaths rather than mix with cars and other vehicles on the road. They cross roads at standard crossings.
KiwiBotStarship Delivery RobotAmazon Scout
Finally some companies are rolling out Car sized Delivery Robots designed to drive on roads and mix with normal vehicles. The REV-1 from Reflection AI is at the smaller end with company videos showing it using both car and bike lanes. Larger is the Small-Car sized Nuro.
REV-1Nuro
Sidewalk Delivery Robots
I’ll concentrate most on Sidewalk Delivery Robots in this article because I believe they are the most mature and likeliest to have an effect on society in the short term (next 2-10 years).
In-building bots are a fairly niche product that most people won’t interact with regularly.
Flying Drones are close to working but it it seems to be some time before they can function safely in a built-up environment and autonomously. Cargo capacity is currently limited in most models and larger units will bring new problems.
Car (or motorbike) sized bots have the same problems as driverless cars. They have to drive fast and be fully autonomous in all sorts of road conditions. No time to ask for human help, a vehicle on the road will at best block traffic or at potentially be involved in an accident. These stringent requirements mean widespread deployment is probably at least 10 years away.
Sidewalk bots are much further along in their evolution and they have simpler problems to solve.
A small vehicle that can carry a takeaway or small grocery order is buildable using today’s technology and not too expensive.
Footpaths exist most places they need to go.
Walking pace ( up to 6km/h ) is fast enough to be good enough even for hot food.
Ubiquitous wireless connectivity enables the robots to be controlled remotely if they cannot handle a situation automatically.
Everything unfolds slower on the sidewalk. If a sidewalk bot encounters a problem it can just slow to a stop and wait for remote help. If that process takes 20 seconds then it is usually no problem.
Starship Technologies
Starship are the best known vendor and most advanced vendor in the sector. They launched in 2015 and have a good publicity team.
The push into college campuses was unluckily timed with many being closed in 2020 due to Covid-19. Starship has increased delivery areas outside of campus in some places to try and compensate. It has also seen a doubling of demand in Milton Keynes. However the company has laid of some workers in March 2020.
Kiwibot
Kiwibot
Kiwibot is one of the few other companies that has gone beyond the prototype stage to servicing actual customers. It is some way behind Starship with the robots being less autonomous and needing more onsite helpers.
Based in Columbia with a major deployment in Berkley, California around the UCB campus area
Robots cost $US 3,500 each
Smaller than Starship with just 1 cubic foot of capacity. Range and speed reportedly lower
Guided by remote control using way-points by operators in Medellín, Colombia. Each operator can control up to 3 bots.
In July 2020 announced rollouts in Atlanta, Georgia and Franklin, Tennessee, but still “initially be accompanied by an Amazon Scout Ambassador”.
Other Companies
There are several other companies also working on Sidewalk Delivery Robots. The most advanced are Restaurant Delivery Company Postmates (now owned by Uber) has their own robot called Serve which is in early testing. Video of it on the street.
Several other companies have also announced projects. None appear to be near rolling out to live customers though.
Business Model and Markets
At present Starship and Kiwi are mainly targeting the restaurant deliver market against established players such as Uber Eats. Reasons for going for this market include
Established market, not something new
Short distances and small cargo
Customers unload produce quickly product so no waiting around
Charges by existing players quite high. Ballpark costs of $5 to the customer (plus a tip in some countries) and the restaurant also being charged 30% of the bill
Even with the high charges drivers end up making only around minimum wage.
The current business model is only just working. While customers find it convenient and the delivery cost reasonable, restaurants and drivers are struggling to make money.
Starship and Amazon are also targeting the general delivery market. This requires higher capacity and also customers may not be home when the vehicle arrives. However it may be the case that if vehicles are cheap enough they could just wait till the customer gets home.
Still more to cover
This article as just a quick introduction of the Sidewalk Delivery Robots out there. I hope to do a later post covering more including what the technology will mean for the delivery industry and for other sidewalk users as well as society in general.
Distribution was not all free software (had bin blobs)
Sun port relied on SunView kernel API
Digital provided binary rendering code
IBM PC/RT Support completed in source form
Why X11 ?
X10 had warts
rendering model was pretty terrible
External Windows manager without borders
Other vendors wanted to get involved
Jim Gettys and Smokey Wallace
Write X11, release under liberal terms
Working against Sun
Displace Sunview
“Reset the market”
Digital management agreed
X11 Development 1986-87
Protocol designed as croos-org team
Sample implementation done mostly at DEC WRL, collaboration with people at MIT
Internet not functional enough to property collaborate, done via mail
Thus most of it happened at MIT
MIT X Consortium
Hired dev team at MIT
Funded by consortium
Members also voted on standards
Members stopped their on develoment
Stopped collaboration with non-members
We knew Richard too well – The GPL’s worst sponsor
Corp sponsors dedicated to non-free software
X Consortium Standards
XIE – X Imaging Extensions
PIX – Phigs Extension for X
LBX – Low Bandwidth X
Xinput (version 1)
The workstation vendors were trying to differentiate. They wanted a minimal base to built their stuff on. Standard was frozen for around 15 years. That is why X fell behind other envs as hardware changed.
X11 , NeWs and Postscript
NeWS – Very slow but cool
Adobe adapted PostScript interpreter for windows systems – Closed Source
Merged X11/NeWS server – Closed Source
The Free Unix Desktop
All the toolkits were closed source
Sunview -> XView
OpenView – Xt based toolkit
X Stagnates – ~1992
Core protocol not allowed to change
non-members pushed out
market fragments
Collapse of Unix
The Decade of Windows
Opening a treasure trove: The Historical Aerial Photography project by Paul Haesler
Geoscience Australia has inherated an extensive archive of hisorical photography
1.2 million images from 1920 – 1990s
Full coverage of Aus and more (some places more than others)
Historical Archive Projects
Canonical source of truth is pieces of paper
Multiple attempts at scanning/transscription. Duplication and compounding of errors
Some errors in original data
“Historian” role to sift through and collate into a machine-readable form – usually spreadsheets
Data Model typically evolves over time – implementation must be flexible and open-minded
What we get
Flight Line Diagrams (metadata)
Imagery (data)
Lots scanned in early 1990s, but low resolution and missing data, some missed
Digitization Pipeline
Flight line diagram pipeline
High resolution scans
Georeferences
Film pipeline
Filmstock
High Resolution scans
Georeference images
Georectified images
Stitched mosaics + Elevation models
Only about 20% of film scanned. Lacking funding and film deteriorating
Other states have similar smaller archives (and other countries)
Many significantly more mature but may be locked in propitiatory platforms
Wanted to go to a tools like dockers, kubernetes that were not well supported by microsoft tools
Gen 3 – Docker Services
Linux
Java / Go
Lots of ways to do stuff
3 different ways of doing everything
Confusing and big tax on developers
Losing knowledge about how the older Reckless stuff worked
A Crazy Idea
Run all the Reckless services in docker
Get rid of one whole generation
What does it take?
Move from .NET Framework to .NET Core
Framework very Windows specific – runtime installed at OS level
Core more open and cross-platform – self contained executable apps
But what about Mono? (Open Source .NET Framework) .
Probably not worth the effort since Framework is the way forward
But a lot of .NET Framework APIs not ported over to .NET Core. Some replaced by new APIs
.Net Standard libraries support on both though, which is lots of them
What Doesn’t port to Core?
Libraries moved/renamed
Some libs dropped
IIS, ASP.NET replaced with ASP.NET Core + MVC
WCF Server communication
Old unmaintained libraries
Luckily Reckless not using ASP.NET so shouldn’t to too hard to do. Maybe not sure a crazy idea.
But most companies don’t let people spend lots of time on Tech Debt.
Asked for something small – 2 weeks of 3 people.
1 week: Hacky proof of concept (getting 1 service to run in .NET Core)
2nd week: Document and investigate what full project would require and have to do
Last Day: Time estimates
Found that Windows ec2 instance were 45%
Cost saving alone of moving from Windows to Linux justied the project
Pitching:
Demo
Detailed time estimates
Proposal with multiple options
Concrete benifits, cost savings, problems with rusty old infra
Microsoft Portability Analyzer
Just run across app and gives very detailed output
icanhasdot.net
Good for external dependencies
Web Hosting differences
OWIN Hosting vs Kestrel
ASP.NET Core DI
Libraries that Do support .NET Standard
Had to upgrade all our code to support the new versions
Major changes in places
OS Differences
case-sensitive filenames
Windows services, event logging
Libararies that did not support .net Standard
Magnum – unmaintained
Topshelf
.NET Framework Libraries can be run under .NET Core using compatibility shim. Sometimes works but not really a good idea. Use with extreme caution
Overall Result
Took 6-8 months of 2-3 people
Everything migrated over.
Around 100 services
78 actually running
43 really needed to be migrated
31 actually needed in the end
Estimated old hosting cost $145k/year
Estimated new hosting costing $70k/year
Actual hosting cost $15k/year
Got rid of almost all the extra infrastructure that was used to support reckless. another $25k/year saved
Advice for cleanup projects
Ask for something small
Test the idea
Demonstrate the business case
Build detailed time estimates
Collecting information with care by Opel Symes
The Problem
People build systems for people without checking our assumptions about people are valid
Be aware of my assumptions, this doesn’t cover all areas
Names
Form “First Name” and “Last Name” -> “Dear John Smith”
Fields Required – should be optional
Should not do character checks ( blocking accents etc )
Check production support emoji.. everywhere
MySQL Character Encodings. Only since 5.5 , default in MySQL 8
Every Database, table and text cloumn and defaults need to be changed to the new character set. Set connection options so things don’t get lost in transfer.
Keynote: Who cares about Democracy? by Vanessa Teague
The techniques for varifying electronic elections are probably to difficult for real voters to use.
The ones that have been deployed have lots of problems
Complex maths for end-to-end varifiable elections – people can query their votes to varify it was recorded – votes are safely mixed so others can’t check.
Swisspost/Scytl System – 2 bugs. One in the shuffling, one in decryption proof
End-to-end verifiable elections: limitations and criticism
Users need to do a lot of careful work to verify
If you don’t do it properly you can be tricked
You can ( usually ) prove how you voted
Though not always, and usually not in a polling-place system
Verification requires expertise
Subtle bugs can undermine security properties
What does all this have to do with NSW iVote?
Used Closed source software
Some software available under NDA afterwards
Admitted it was affected by the first Swiss bug. This was when early voting was occuring
Also so said 2nd Swiss bug wasn’t relevant.
After code was available they found it was relevant, a patch had been applied but it didn’t fix the problem
NSW law for election software is all about penalties for releasing information on problems.
Victoria has passed a bill that allows elections to be conducted via any method which is aimed at introducing electronic voting in future elections
Electronic Counting of Paper Records
Keynote: Who cares about Democracy? by Vanessa TeagueVarious areas have auditing software that runs against votes
This only works on FPTP elections, not Instant-runoff elelctions
Created some auditing software what should work, this was testing using some votes in San Francisco elections
A sample of ballots is taken and the physical ballot should match what the electronic one said it is.
Australian Senate vote
Auditing not done, since not mandated in law
What can we do
Swiss has laws around transparency, privacy and varivication
NSW Internet voting laws is orientated around protecting the vendors by keeping the code secret
California has laws about Auditing
Australian Senate scrutineering rules say nothing about computerised scanning and auting
Aus Should
Must be a meaningful statistical audit of the paper ballots
with meaningful observation by scrutineers
In Summary
Varifiable e-voting at polling place is feasible
over the Internet is an unsolved problem
The Senate count at present provides no evidence of accuracy
but would if a rigorous statistical audit is mandated
How else to use verifiable voting technology?
Crowsourcing amendments to legislation with a chance to vote up or down
Open input into parliamentary quesions
A version for teenagers to practice debating what they choose