Since I posted by idea for two Auckland light Metro lines I’ve had some feedback and made some updates. This is the new version of the article. At the bottom of this article I’m written about the changes and reasoning behind them. You can also read my article on Light Metro Technology to get more information about the technology I am proposing be used.
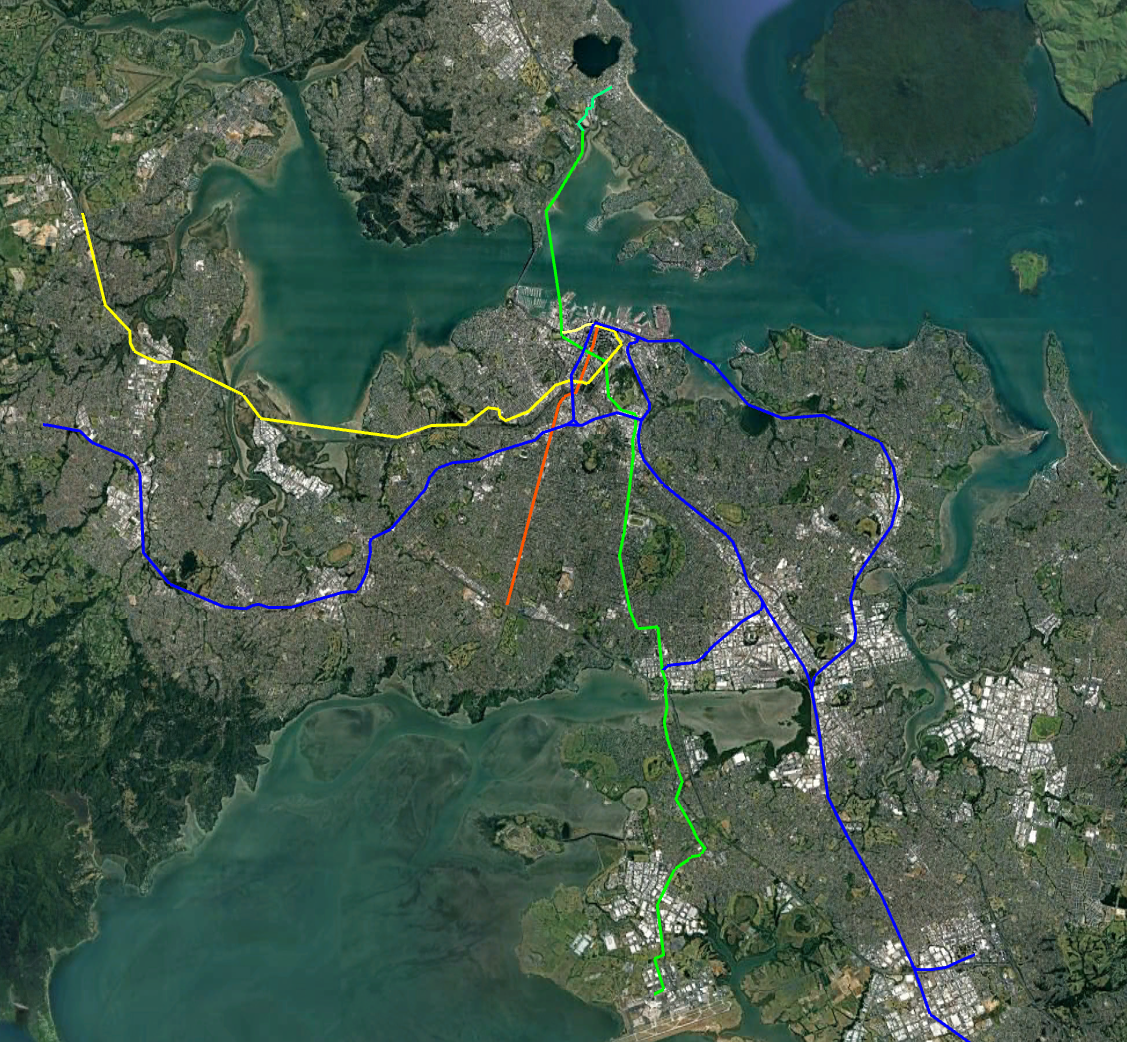
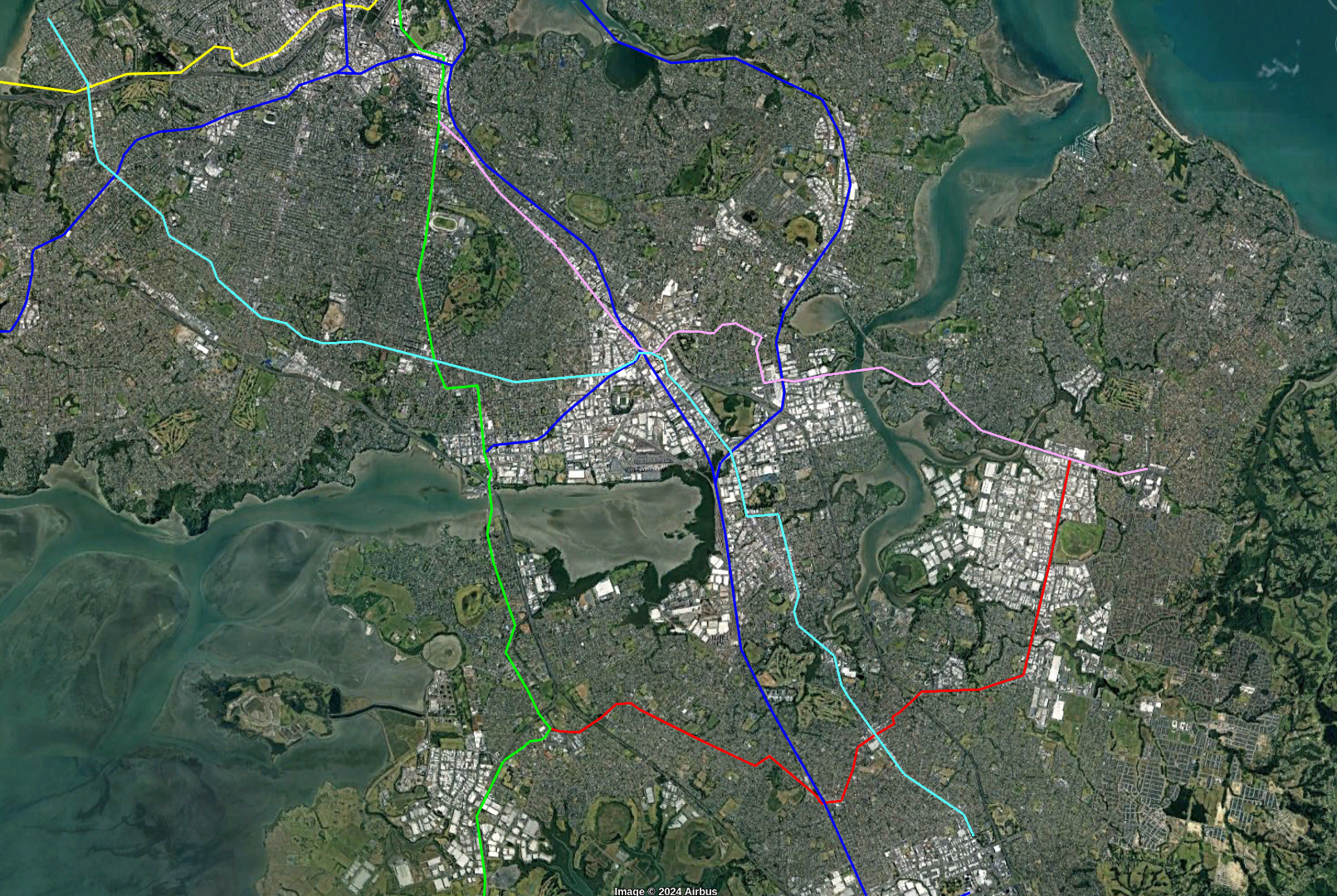
Below is the new network I am planning as a basis for Auckland. It consists of
The existing Heavy Rail network (Dark blue).
A street running light Rail along Queen Street and Domain Rd (Red)
A North/South from the North Shore to the CBD and then the Airport (Green)
A Western line from the CBD to Westgate ( yellow )
In this post I’ll cover the North/South line. Not that all pictures/maps in the article can be opened to see the larger version
Light Metro Technology
As outlined in a previous article Light Metro is Automated (driverless), Grade Separated with Short Trains and High Frequencies. It is well suited to Auckland where requirements exceed Light Rail but a full metro would be overkill.
The key advantages of Light Metro over street running light rail is it’s high capacity, frequency and higher speed. Attempting to push Light Rail beyond it’s natural sweet-spot result in a grade-separated system that costs as much as Light Metro but is worse and often costs more to run.
The below table shows the capacity of a Light Metro line (in each direction). For Auckland the stations outside the CBD could be serviced by buses to further increase coverage area. Trains could start at short length and frequency increased as high as possible before longer trains should be used.
Headway / Trains per Hour
2 Cars
3 Cars
4 Cars
6 Cars
5 min / 12 tph
2,400
3,600
4,800
7,200
3 min / 20 tph
4,000
6,000
8,000
12,000
2 min / 30 tph
6,000
9,000
12,000
18,000
90 sec / 40 tph
8,000
12,000
16,000
24,000
Max Passengers per hour per direction
If the system is run with 4-car trains ( 52m long, 400 people ) then each line has the capacity over double one of the major Auckland motorways such as the Western or Southern.
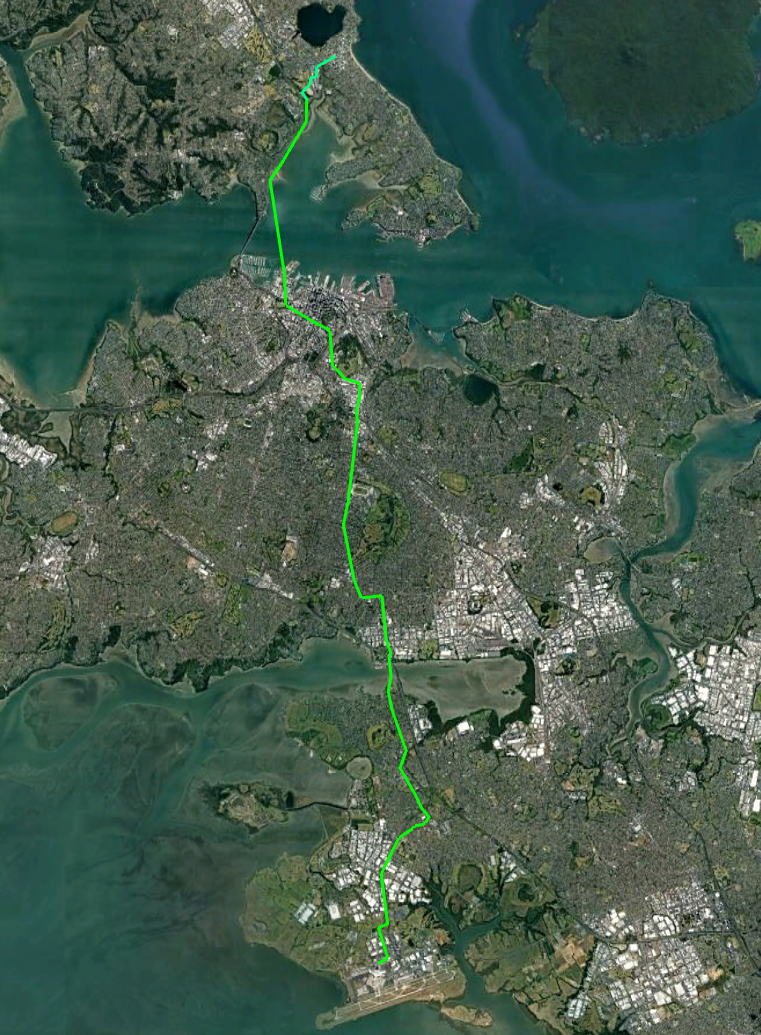
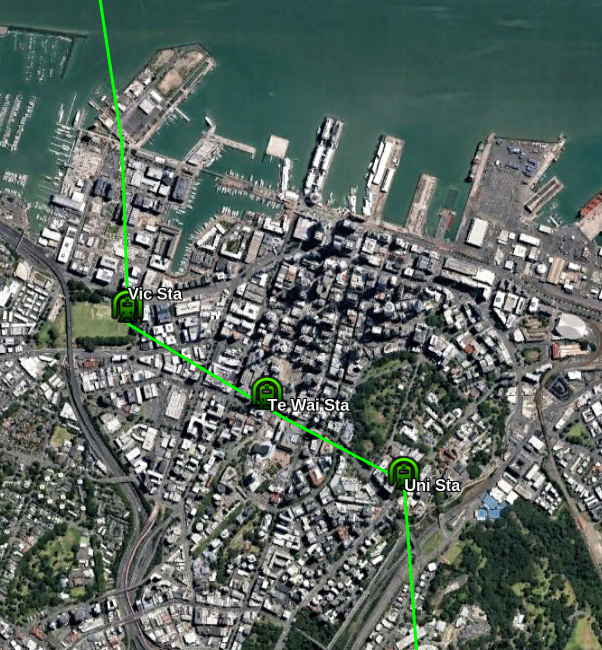
Line 1 – A North/South Metro line from Takapuna to the Airport
This line would start from Takapuna run under the CBD and connect to the Airport in the South.
The line would be grade separated above the road as much as possible since this is cheaper than under-grounding. It would be underground though the central city however.
Total length would be around 28km of which around 6.2km would be underground. Cost would be something like $15b
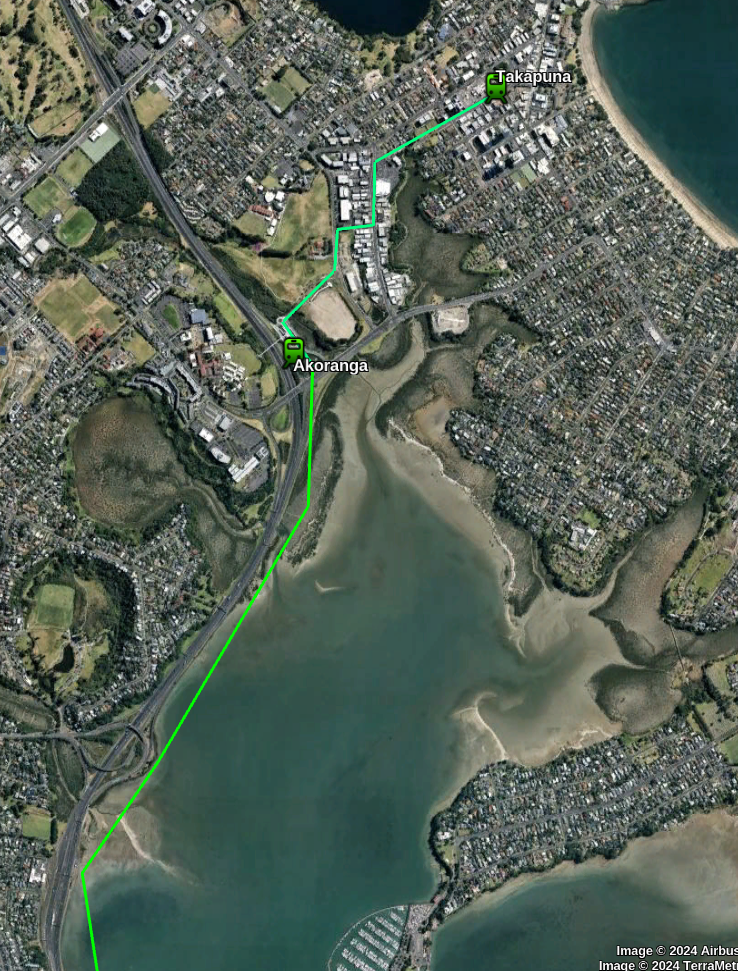
Northern Section
This would be completely overhead and mainly above roadways. It would start from a station at Takapuna and then another station at the Existing Busway station of Akoranga.
The route would then go between the motorway and the sea until it reaches a tunnel across the harbour near Northcote Pt.
See section below for discussion as to the advantages and disadvantages of a tunnel vs a bridge for crossing Waitemata Harbour.
A route to Takapuna avoids duplicating the existing busway. Going off the 2024 bus statistics around 20% of the busway passengers go to Takapuna and Milford and it is likely some more would change from the bus to metro at Akoranga station if the Metro better served the southern part of their journey.
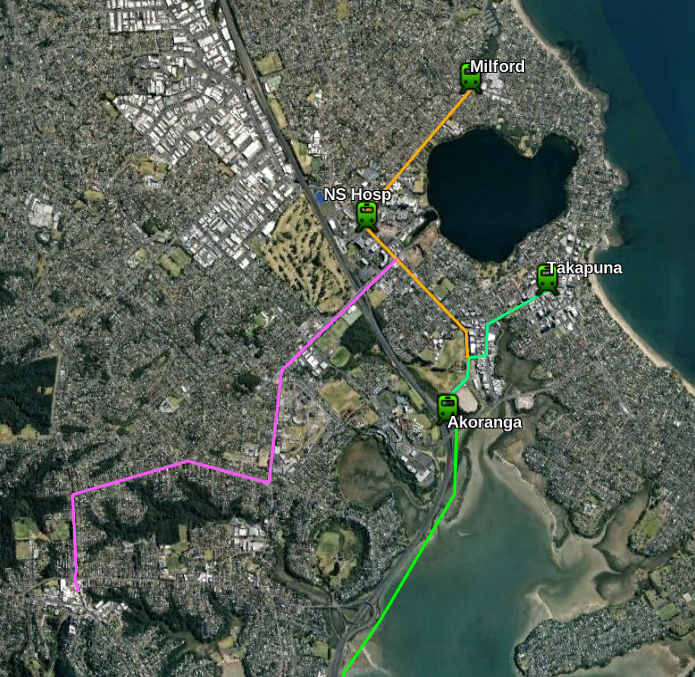
I have mapped out some possible extensions to this line but there are several other options.
A natural extension to this line would be a line to the North Shore Hospital and then Milford.
A line to Northcote and Birkenhead could also be built, although this line unfortunately goes the wrong way for Northcote and Birkenhead people going into the city.
Later lines might go down Wairau Rd to the Wairau Valley
City Section
The first station will be under the eastern end of Victoria Park. Ideally it should have entrances on the far sides of Fenshaw, Halsey and Victora Streets so passengers do not have to cross busy roads to reach it.
The Te Waihorotiu CRL station is apparently already future-proofed with space for a North/South line. The station will effectively be the centre of the Auckland System. There should also be a surface Light Rail line nearby on Queen Street.
The University station would be quite deep (because the line would be under Queen Street and the Grafton Valley Motorway) and probably be an elevator-only station.
I’ll cover how lines intersect later
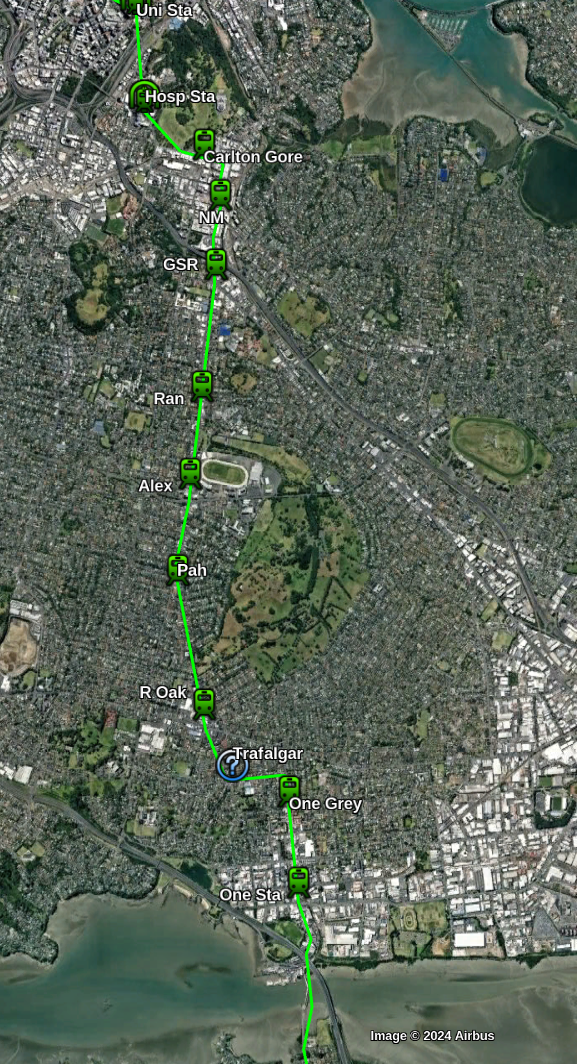
The Southern Isthmus
South of the University the line has a station on the corner of Park Road to serve the Hospital, The Grafton Campus and nearby area. This station may be deep enough to also be elevator-only.
The line comes out of it’s tunnel just after the domain and is now elevated until it reaches the Airport.
The first station is on Carlton Gore road to serve Northern Newmarket. Then there is Station in central Newmarket connected to the existing rail station.
South of Newmarket the line will travel above Manukau Rd and continue South through Royal Oak and Onehunga.
Possible stations could be (at roughly 1km intervals):
Near corner Manukau and Great South Road
Corner of Manukau Rd and Ranfurly Road
Corner of Manukau Rd and Queen Mary Ave (Alexandra Park, Green Lane West Rd)
Corner of Manukau and Pah Roads
Royal Oak Mall
Corner of Manukau Rd and Trafalgar St ( optional / future-proofed )
Onehunga Mall Road near Grey Street
Onehunga Station
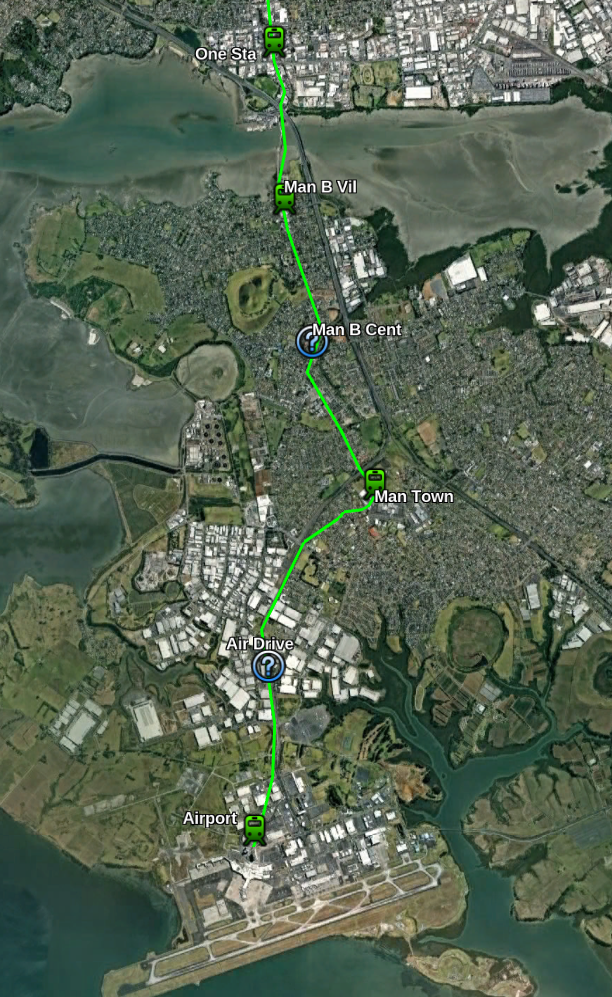
Mangere Section
The southernmost section crosses the Mangere harbour near the current bridges (No special bridge should be needed since it will be fairly low) and has a station at Mangere Bridge Village just South of the crossing.
The line then continues south along the Coronation Rd, McKenzie Rd and Bader Drive with the provision of a future station near Miller Road.
The station follows Bader Drive over the motorway to a station in Mangere town Centre. It then cuts over some houses (which will need to be purchased) back to the motorway and follows it South.
I’ve future proofed a station in the airport industrial area after which the line goes underground between Landing Drive and Ihumatoa Road for about 1km to a station under the airport.
The Depot for the Line would probably be best placed somewhere between the Airport and Mangere Town Center Station.
Bridge vs Tunnel for the Waitemata Harbour crossing
The plan currently has the line using a tunnel. This is probably about $1b more expensive than a bridge and makes it very difficult to provide a walking or cycling option.
The reason for this is that currently the Upper Harbour (West of the Auckland Harbour Bridge) has Chelsea Sugar Refinery and the Kauri Point Armament Depot. Both of these much be reachable by large ships. This requires a clearance of any bridge over the water to be similar to the current bridge’s 43 metres.
Since trains have problems with gradients much over 3% this would require over 1km of climb to reach which is almost impossible to fit south of the ship channel.
If the Sugar Refinery and Ammunition Depot can be moved then a lower bridge quickly becomes the best option. With a saving of over $1b it might be better to pay for them to move. However I have kept things as a tunnel for now.
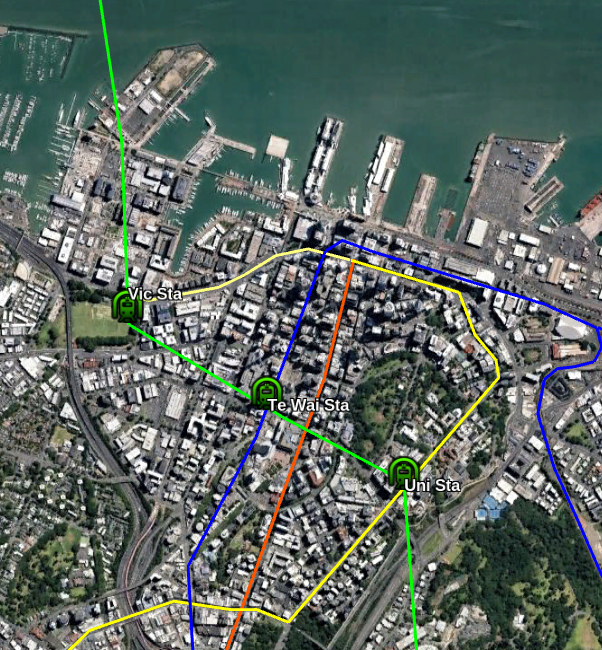
CBD stations and line intersections
This maps shows the other lines including the existing lines, a Queen St Light Rail and my proposed Western line.
The Victoria Park station as well as serving the immediate area supports transfers to the Western Line to get to lower-Queen Street and transfer to College Hill and Northcote buses
The Te Waihorotiu Station allows access to Aotea Square area and transfers to the CRL and Light Rail
The University Station serves the Universities and allows transfers to the Western line and Symonds Street Buses.
Southern Branches and Other Lines
As the lines gets further South the demand on the single line will be reduced. So I propose that the line eventually branch just South of Newmarket
The new line would go down Great South Road as far as the existing Penrose Station and then East along Penrose Rd to meet the Sylvia Park station. It would then go East to Pakuranga and down Ti Rakau Dr to Botany. The existing Greenlane and Remuera stations could perhaps be replaced by Stations on the line
Because Light Metro can handle very high frequency, capacity on both branches would be high. For example trains could be every 2 minutes in the central areas and every 4 minutes on the branches
I’ve sketched out some later lines mainly to make sure the planned line has room for growth.
The first is a line from Mangere Town Center to Botany that goes though Papatoetoe and Otara.
The other is a cross town line that Starts in Point Chevalier and Follows Carrington, Mt Albert, Mt Smart and Great South Roads to Manakau City.
Penrose station would be a natural intersection point for two of the lines (and the existing heavy rail) and could be upgraded to be a major transfer station.
Keeping the cost down
It is important to keep the cost of the line down as much as possible to improve it’s chances of being built. Especially the urge must be avoid to create expensive monumental stations or under-grounding more sections to avoid perceived disruption.
I propose the following measures
Elevated Line instead of Underground where possible.
A standard simple design for elevated stations. Cheap colour and art can provide differentiation for a small percentage of the cost
Simple underground stations
Leaving space for some stations to be built later
Relatively small elevated stations. Perhaps only with 60m (4 car) platforms being initially built but space left for larger additions later.
Driverless operation
Using Standard off-the-shelf Train systems that are already deployed elsewhere with minimal changes
Note that driverless operation allows frequent trains which in turn allow shorter trains which means smaller cheaper stations.
Costing
I put my costs are what I consider realistic New Zealand levels. Some countries are able to build for less but I’ve listed what I hope New Zealand can build for.
$1b/km underground lines
$300m/km for elevated
Stations: $25m elevated, $250m underground
$1b/km + $500m extra for Harbour Tunnel
North/South Line length by type of track
4.1 km Overhead from Takapuna to the Tunnel
A 2.4 km tunnel across the Harbour
A 3.7 km tunnel under the CBD
8.6 km to the northern shore of Mangere Inlet
7.7 km overhead across the inlet and South
1 km underground near the airport
Total
4.7 km underground
2.4 km Harbour tunnel
20.4 km overhead
Total cost
4.7 km underground at $1b/ km = $4.7b
2.4 km Harbour Tunnel = $2.9b
20.4 km of overhead line at $300m/km = $6.1b
13 overhead stations at $25m each = $325m
5 underground stations at $250m each = $1250
Total = 15.2b
General observations and conclusions
Travel times for this sort of Metro are around 30km/h including stops although this line has fewer stops than most and some long stretches so should be a bit faster. Assuming 30km/h we get:
Airport to Te Waihorotiu station 19.4km = 38 minutes
Takapuna to Te Waihorotiu station 8.1km = 16 minutes
Currently the Airport takes around 1h 30m via public transport and 40 minutes for the Skydrive private Airport bus outside of peak times. The bus from Takapuna takes 20-25 minutes. Remember that the metro will have very high fequency so waiting for the next train will only be a couple of minutes.
I’ve tried to make the route realistic and useful. As far as I can tell all the climbs are within the capacity of a typical metro system. However some of the corners may be a little tight and additional space may be needed.
While only a small proportion of the passengers will travel to and from the airport I think the service will be great for this. Some people do express concern about room for luggage but riders manage on other systems around the world.
I think that this line and the Western line has a great potential to improve transport across Auckland. It will take pressure off the Northern Busway and also add huge capacity to the South West and Airport.
My next article will cover my proposal for a Western Line
Changes since previous version
General
I’ve made 3 stations on the line optional to save cost and increase speed
North Shore
Instead of replacing the Northern busway I’ve updated the line to go to Takapuna and eventually Milford instead. This will be around 1.7km from Akoranga Station rather than 10km so it should say $2-3 billion from the initial build and mean that we augment the Northern Busway rather than replace it..
I’ve included a few possible routes but there are a lot of options both for the initial route into Takapuna and future lines.
Central City
I’ve replace the Wynyard and Victoria stations with a single station under the east of Victoria Park. It would also have a similar service area to the two stations.
I’ve also rerouted the end of the Western Line to go along Fenshaw St rather than across the Viaduct Basin
Auckland Hospital
My original plan had the line going South from the University, under the motorway and Museum and emerging on the North of Newmarket
However skipping the hospital seems a bad idea. It is a huge trip generator not just for the hospital but for the Grafton Campus and other businesses and housing nearby.
So I’ve updated the route to have a station under the corner of Park road and the line emerging on Carlton Gore road with a station near the bottom of that road.
Mangere
I’ve changed Mangere town centre to be directly on the line instead of a short branch. This does mean the line goes through housing to get back on the motorway.
A fun romp though the unexpected 3rd Act of 60s and 70s Music Stars since 1985. Full of amusing stories delivered with Hepworth’s usual witty style 4/5
An insider’s stories of Facebook (and a Shark attack). Lots of nuts stuff and good yarns the reflect pretty negatively. Although the author seems too good to be true. 4/5
From Friday 24th January to Sunday 26th January 2025 I attended the OzMoot 2025 conference in Melbourne.
OzMoot is a small conference centered around the works of J.R.R Tolkien and related topics. It is run by Hern Ennorath (The Australian Tolkien fan organisation) in partnership with Signum University who do various activities including running similar events around the world.
Overview
Around 30 people attended in person with a similar number online. The venue was a community hall. Cost was $US 100 per person for the two and a half days of the conference.
The programme mostly consisted of talks on various topics ( Scroll down here to see the schedule ) with coffee/biscuits for morning and afternoon tea and a break for lunch which most people took at the nearby cafes (or brought food back to the venue). In the evening there were two dinners (one at a restaurant and another at the home of an attendee) plus there was an ad-hoc dinner on the last day some attended.
When I saw the “mostly talks” there were several events that were not straight presentations. They included several talks that included music (as per the theme of the conference) plus straight musical performances, a costume parade, Tolkien readings and a trivia competition.
The Hall also had tables setup. One with books (and other items) for sale, a second with collectables displayed and a 3rd with a jigsaw puzzle (which we collectively did not finish)
The event was Hybrid with streaming via Zoom and an active Slack for the duration of the event.
Items for sale
Collectables Display
Impressions
The conference was described as “In the grey area between fan convention and academic conference” which is pretty accurate. Many of the talks are quite academic although by no means all of them and the talks are mostly accessible even if you are only a casual fan (or been dragged along by your Mum in two cases this year).
You note that not all the talks are directly Tolkien related. eg the Keynote was analyzing Rap/HipHop Music.
“Tolkien Professor” Corey Olsen analyzing Rhyming in Rap Music
This conference was the third I’ve attended. I went to 2023 online and attended OzMoot 2024 in Sydney in person.
The whole event is great and the people are very welcoming. The attendees are a wide range of ages and have lots of interests and skills outside the world of Tolkien.
I would recommend the conference if you are interested in Tolkien and in Australia or New Zealand. If you want to start off slow I’d suggest attended one of the Moots online. They mostly last a day and cost around $US25. Signum also does several free weekly streams/podcasts and paid online courses.
Next year’s OzMoot is planned for late-January 2026 in Canberra and there are tentative plans for 2027 to be held in Wellington. I hope to attended both events.
2025 was the 3rd Everything Open (EO) to be held and around 300 people attended. The Conference opened each day with a keynote and then split into 3 streams of talks plus a tutorial stream. Talks range fairly widely, the official blurb is a “conference focused on open technologies, including Linux, open source software, open hardware and open data, and the communities that surround them“
The venue was the Adelaide Convention Centre which had plenty of room and was nice enough. They main train lines for Adelaide ran under it with around 8 tracks under the venue. There were good food options a few minutes walk away since the venue is close to the Adelaide CBD.
Accommodation was fairly good. I got a hotel for $150/night about 10 minutes walk away that was near restaurants etc.
Content and attending
I really enjoyed the keynotes this year. All three speakers were interesting and and had great delivery. I also felt there talks were all good and there are several I missed that I’d like to catch-up if/when the videos are out.
I publish my (rough) notes from talks I attend to this blog. A list of here
Unfortunately I’m still masking (as were about 5% of attendees) so I probably didn’t participate in the Hallway track as much I would in the past. It was also fairly small due to relatively small numbers at the conference (see below)
The only organised evening event was the Penguin dinner at the Zoo. Unfortunately we didn’t get to see animals, just the food venue (drinks and chat followed by dinner)
Thoughts on the conference Format and Future
While EO attracted around 300 people which was almost double last year (held in the fairly remote city of Gladstone) but still less than what half a typical LCA attracted before Covid.
Unfortunately EO is still a step down from LCA. There were very few attendees from outside Australia and New Zealand. Part of this is due to disruption of conference going during COVID and part due to the general economic conditions but I think there were some other factors
At LCA Miniconfs were a good way to attract people and provide targeted content. People would come for the Kernel, GLAM or Sysadmin Miniconf (disclaimer I helped run the latter) and stay for the rest of the conference. They could tell their boss they were going to the “Work-related Miniconf” at LCA and staying for the rest.
The lack of Miniconfs also meant the conference was less nimble. While several talks were about LLMs and AI, in the past a LCA would probably have had 1-2 days of Miniconfs devoted to this hot topic (perhaps one day technical for users and a 2nd day for users and policy). Eg in 2020 there was a Kubernetes orientated Miniconf.
The conference being only 3 days and 3+1 streams rather than 3 days of 5+1 (plus 2 days of Miniconfs) seen at later LCAs also means people get less for their buck. Especially since travel will make up a significant cost for many attendees.
The inclusive EO brand also trying to reach out to a broader group means that the conference is less attractive to a technical user. The Irony is of course that LCA was a nominally technical conference with a lot of non-technical content while EO is a branded as a broad conference that is still probably 75% technical talks.
I’ll probably come back next year if the event is held. However the event had yet to be arranged due to lack of a bid. However a group was formed after the this year’s conference and it is likely that an event will happen in Canberra in 2026.
The Linux Australia AGM covered several problems with the conference (see The Linux Australia 2025 AGM video ) including difficulty finding people to run it, problems finding sponsors and the format. Questions were asked about bringing Miniconfs and problems with them were highlighted.
Overall it is difficult to tell where things are going. The conference is fairly successful but struggling to be sustainable. Personally I am not sure on the best path. Perhaps splitting the conference into two could work. Something like 2 days of Linux.conf.au, one day of Miniconfs and then 2 days of EO. But anything would required people to volunteer to help which is difficult right now.
First Poem – Athelas When the black breath blows and death’s shadow grows and all lights pass, come athelas! come athelas! Life to the dying In the king’s hand lying!
When the moon was new and the sun young of silver and gold the gods sung: in the green grass they silver spilled, and the white waters they with gold filled. Ere the pit was dug or Hell yawned, ere dwarf was bred or dragon spawned, there were Elves of old, and strong spells under green hills in hollow dells they sang as they wrought many fair things, and the bright crowns of the Elf-kings. But their doom fell, and their song waned, by iron hewn and by steel chained. Greed that sang not, nor with mouth smiled, in dark holes their wealth piled, graven silver and carven gold: over Elvenhome the shadow rolled.