Allen Geer, Amanda Baker – Continuously Testing govt.nz
- Various .govt.nz sites
- All Silverstripe and Common Web Platform
- Many sites out of date, no automated testing, no test metrics, manual testing
- Micro-waterfall agile
- Specification by example (prod owner, Devops, QA) created Gherkin tests
- Standardised on CircleCI
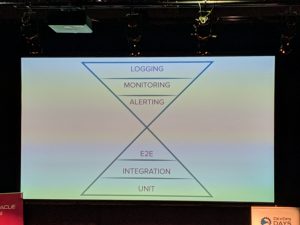
- Visualised – Spec by example
- Prioritised feature tests
- Ghirkinse
- Test at start of dev process. Bake Quality in at the start
- Visualise and display metrics, people could then improve.
- Path to automation isn’t binary
- Involve everyone in the team
- Automation only works if humanised
Jules Clements – Configuration Pipeline : Ruling the One Ring
- Desired state
- I didn’t quite understand what he was saying
Nigel Charman – Keep Calm and Carry On Organising
- 71 Conferences worldwide this year
- NZ following the rules
- Lots of help from people
- Stuff stuff stuff
Jessica DeVita – Retrospecting our Retrospectives
- Works on Azure DevOps
- Post-mortems
- What does it mean to have robust systems and resilience? Is resilience even a property? It just Is. When we fly on planes, we’re trusting machines and automation. Even planes require regular reboots to avoid catastrophic failures, and we just trust that it happen
- CEO after a million dollar outage said “Can you get me a million dollars of learning out of this?”
- After US Navy had accidents caused by slept deprivation switched to new watch structure
- Postmortems are not magic, they don’t automatically make things change
- http://stella.report
- We dedicate a lot of time to to below the line, looking at the technology. Not a lot of conversation about above-the-line things like mental models.
- Resilience is above the line
- Catching the Apache SNAFU
- The Ironies of Automation – Lisanne Bainbridge
- Well facilitated debriefings support recalibration of mental models
- US Forest Service – Learning Review – Blame discourages people speaking up about problems
- We never know where the accident boundary is, only when we have crossed it.
- SRE, Chaos Engineer and Human Factors help hadle
- In postmortems please be mindful of judging timelines without context. Saying something happened in a short or long period of time is damanging
- Ask “what made it hard to get that team on the phone?” , “What were you trying to achieve”
- Etsy Debriefing Guide – lots of important questions.
- “Moving post shallow incident data” – Adaptive Capacity Labs
- Safety is a characteristics of Systems and not of their components
- Ask people about their history, ask every person about what they do and how they got there because that is what shapes your culture as an organisation