Various talks I watched from their YouTube playlist.
Application Autoscaling Made Easy With Kubernetes Event-Driven Autoscaling (KEDA) – Tom Kerkhove
I’ve been using Keda a little bit at work. Good way to scale on random stuff. At work I’m scaling pods against length of AWS SQS Queues and as a cron. Lots of other options. This talk is a 9 minute intro. A bit hard to read the small font on the screen of this talk.
Autoscaling at Scale: How We Manage Capacity @ Zalando – Mikkel Larsen, Zalando SE
- These guys have their own HPA replacement for scaling. Kube-metrics-adapter .
- Outlines some new stuff in scaling in 1.18 and 1.19.
- They also have a fork of the Cluster Autoscaler (although some of what it seems to duplicate Amazon Fleets).
- Have up to 1000 nodes in some of their clusters. Have to play with address space per nodes, also scale their control plan nodes vertically (control plan autoscaler).
- Use Virtical Pod autoscaler especially for things like prometheus that varies by the size of the cluster. Have had problems with it scaling down too fast. They have some of their own custom changes in a fork
Keynote: Observing Kubernetes Without Losing Your Mind – Vicki Cheung
- Lots of metrics dont’t cover what you want and get hard to maintain and complex
- Monitor core user workflows (ie just test a pod launch and stop)
- Tiny tools
- 1 watches for events on cluster and logs them -> elastic
- 2 watches container events -> elastic
- End up with one timeline for a deploy/job covering everything
- Empowers users to do their own debugging

Autoscaling and Cost Optimization on Kubernetes: From 0 to 100 – Guy Templeton & Jiaxin Shan
- Intro to HPA and metric types. Plus some of the newer stuff like multiple metrics
- Vertical pod autoscaler. Good for single pod deployments. Doesn’t work will with JVM based workloads.
- Cluster Autoscaler.
- A few things like using prestop hooks to give pods time to shutdown
- pod priorties for scaling.
- –expandable-pods-priority-cutoff to not expand for low-priority jobs
- Using the priority-expander to try and expand spots first and then fallback to more expensive node types
- Using mixed instance policy with AWS . Lots of instance types (same CPU/RAM though) to choose from.
- Look at poddistruptionbudget
- Some other CA flags like scale-down-utilisation-threshold to lok at.
- Mention of Keda
- Best return is probably tuning HPA
- There is also another similar talk . Note the Male Speaker talks very slow so crank up the speed.
Keynote: Building a Service Mesh From Scratch – The Pinterest Story – Derek Argueta
- Changed to Envoy as a http proxy for incoming
- Wrote own extension to make feature complete
- Also another project migrating to mTLS
- Huge amount of work for Java.
- Lots of work to repeat for other languages
- Looked at getting Envoy to do the work
- Ingress LB -> Inbound Proxy -> App
- Used j2 to build the Static config (with checking, tests, validation)
- Rolled out to put envoy in front of other services with good TLS termination default settings
- Extra Mesh Use Cases
- Infrastructure-specific routing
- SLI Monitoring
- http cookie monitoring
- Became a platform that people wanted to use.
- Solving one problem first and incrementally using other things. Many groups had similar problems. “Just a node in a mesh”.
Improving the Performance of Your Kubernetes Cluster – Priya Wadhwa, Google
- Tools – Mostly tested locally with Minikube (she is a Minikube maintainer)
- Minikube pause – Pause the Kubernetes systems processes and leave app running, good if cluster isn’t changing.
- Looked at some articles from Brendon Gregg
- Ran USE Method against Minikube
- eBPF BCC tools against Minikube
- biosnoop – noticed lots of writes from etcd
- KVM Flamegraph – Lots of calls from ioctl
- Theory that etcd writes might be a big contributor
- How to tune etcd writes ( updated –snapshot-count flag to various numbers but didn’t seem to help)
- Noticed CPU spkies every few seconds
- “pidstat 1 60” . Noticed kubectl command running often. Running “kubectl apply addons” regularly
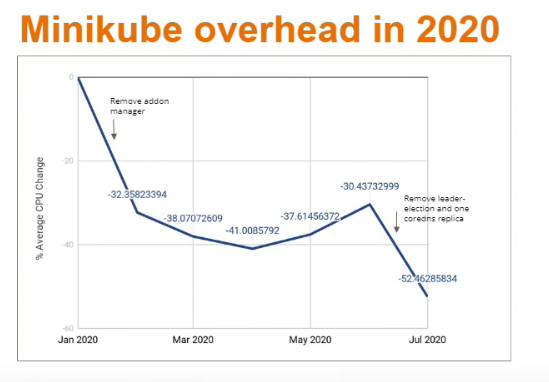
- Suspected addon manager running often
- Could increase addon manager polltime but then addons would take a while to show up.
- But in Minikube not a problem cause minikube knows when new addons added so can run the addon manager directly rather than it polling.
- 32% reduction in overhead from turning off addon polling
- Also reduced coredns number to one.
- pprof – go tool
- kube-apiserver pprof data
- Spending lots of times dealing with incoming requests
- Lots of requests from kube-controller-manager and kube-scheduler around leader-election
- But Minikube is only running one of each. No need to elect a leader!
- Flag to turn both off –leader-elect=false
- 18% reduction from reducing coredns to 1 and turning leader election off.
- Back to looking at etcd overhead with pprof
- writeFrameAsync in http calls
- Theory could increase –proxy-refresh-interval from 30s up to 120s. Good value at 70s but unsure what behavior was. Asked and didn’t appear to be a big problem.
- 4% reduction in overhead